
How Startups Can Win with Continuous Feedback
Leveraging RL and Agile Iteration to Dominate Vertical Markets

Startups win based on their ability to spot underserved opportunities, especially in areas where larger organizations move slowly or overlook nuanced needs. In the AI landscape, this means identifying workflows that benefit from deep specialization and ongoing refinement.
Winning here requires more than a one-time training run, it requires designing a system that learns in production. And that system lives or dies by two things:
The problem you choose to solve: picking a workflow where depth beats breadth.
The feedback loop: how fast and reliably you can collect, evaluate, and integrate performance data.
Start with the Right Problem
By narrowing your focus to a specific industry or even a single workflow, you can design models that capture 100% of the relevant problems in that vertical. Choosing a single workflow doesn’t mean you are going after a small market size. Instead, it’s about finding a narrow focus area that is shared across the industry. That’s your wedge, from there you can integrate yourself deeply into your customers’ operations and expand up or down.
In freight forwarding, for example, a startup could start by optimizing carrier selection for time-sensitive freight, such as perishable goods, where the model dynamically evaluates carriers based on real-time data like transit times, spoilage risk, port congestion, and cost, continuously improving through shipper feedback. Unlike general models that treat carrier selection as a static optimization problem, this hyper-specialized approach delivers immediate value by reducing losses and delays. As the model gathers proprietary data (e.g., carrier performance metrics, user corrections, and supply chain disruptions) it can expand to handle route optimization, customs documentation, and real-time tracking, ultimately replacing the traditional Transportation Management System (TMS) by offering a fully integrated, AI-driven solution that adapts daily to customer needs.
These problems are too specific and workflow-dependent for a frontier model to excel without significant customization. This is where your advantage shows up:
Higher accuracy on edge cases your customers actually care about.
Tight integrations with industry-specific tools and data sources (e.g., TMSs for freight forwarding)
Workflow logic and decision-making that general-purpose models will never prioritize.
For this, a smaller, vertical-specific model can outperform by being deeply embedded in the day-to-day realities of the industry, allowing for faster experimentation and refinement than larger, more generalized systems.
Designing a Continuous Feedback Loop
A model’s advantage compounds over time if you have a tight, reliable loop for collecting, evaluating, and acting on feedback. The goal is to turn every interaction into a data point that makes the model better.
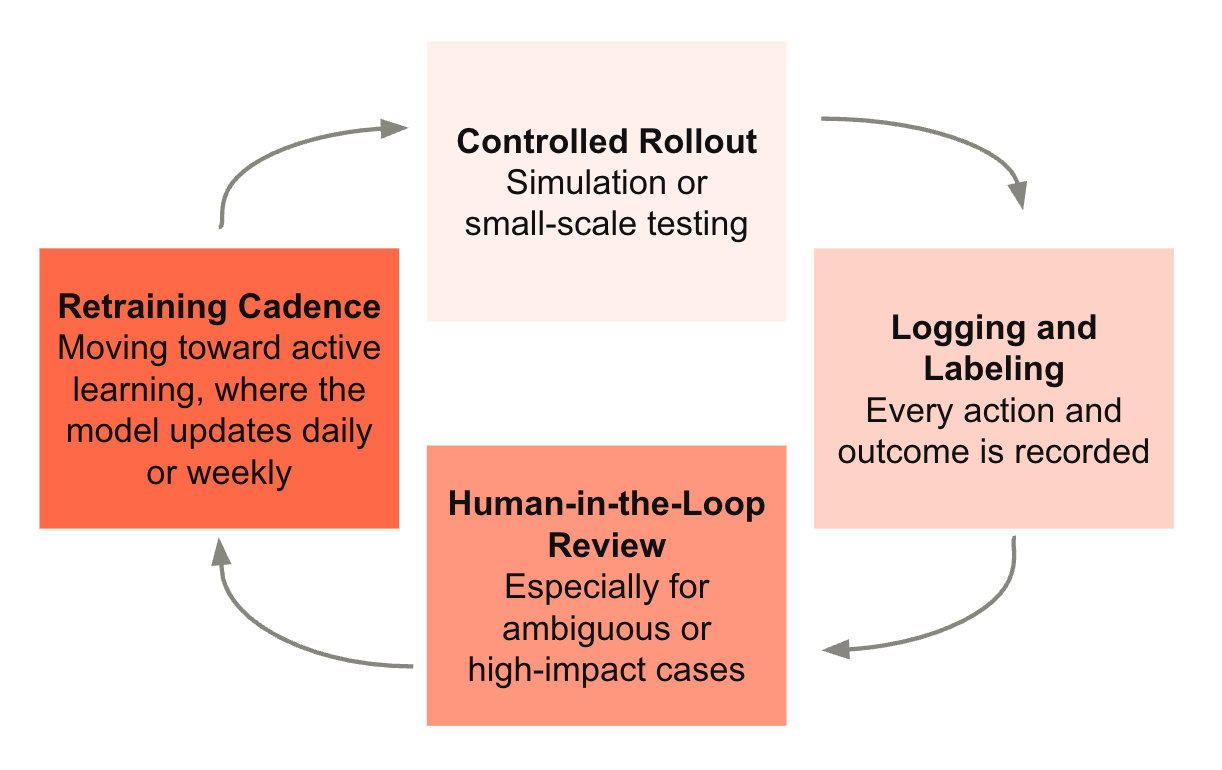
A strong loop typically includes:
Controlled rollout: simulation or small-scale testing. This could involve simulations using historical data or a limited deployment with a small group of users to gather initial insights without exposing the entire operation to potential errors.
Logging and labeling: every action and outcome is recorded. This creates a rich dataset for analysis and retraining, ensuring no valuable signal is lost.
Human-in-the-loop review: especially for ambiguous or high-impact cases. This results in higher accuracy and provides better feedback to refine the model.
Retraining cadence: moving toward active learning, where the model updates daily or weekly. This keeps the AI aligned with evolving user needs and real-world conditions.
Gradual expansion: with monitoring and guardrails.
The faster this loop spins, the more defensible your advantage becomes.
If you have the right data and the right loop, you can choose the best optimization method for the job: RL excels at preference-driven and stylistic tuning, while supervised fine-tuning is often better for binary or correctional workflows. In practice, the two can complement each other: fine-tune for correctness, then use RL to refine judgment and nuance.
Startups can foster closer proximity to customers within a vertical and that enables these loops to run more efficiently.
Training the Right Evaluators
Your feedback loop is only as good as its data. That means your evaluators (whether human or AI) need:
Domain expertise: they should speak the same jargon and understand the same context as the end users.
Clear, consistent criteria: feedback signals can’t be noisy or contradictory.
Bias awareness: avoiding easy-to-game or misleading reward patterns. This is around designing rewards to reflect decision quality, not just outcomes.
In specialized workflows, the best graders are often former practitioners. Customers can also grade user-facing outputs, but exposing them to the model’s internal decision logic carries competitive and perceptual risks. Strong evaluators also help shape the reward function so it reflects decision quality rather than just superficial metrics. In the freight forwarding example, a routing model rewarded only for fastest delivery might always choose premium, expedited options or direct routes that bypass cost-effective consolidation hubs. This looks good on the speed metric, but it ignores cases where the SLA isn’t urgent, the added cost outweighs the benefit, or shippers prefer eco-friendly routes to align with sustainability goals.
Why This Matters Now
You won’t out-model the big AI labs on general intelligence. But you can beat them on depth, speed of iteration, and customer-specific performance.
Frontier model providers can’t optimize for everyone at once without trade-offs. It’s like squeezing a balloon – push in one spot to improve performance for a certain group, and another part bulges out, worsening the experience for others.
By embedding continuous feedback loops into real-world workflows, you build a model that is:
Better for your specific use case.
Always improving with each interaction.
Smaller, cheaper, and faster than a frontier model for your domain.
The best software will soon have embedded feedback mechanisms, moving beyond generic thumbs-up or thumbs-down buttons to richer, context-specific signals woven directly into the workflow. Every interaction, correction, and usage pattern becomes training data the system can use to improve continuously.
Frontier models are powerful but often constrained by their scale, requiring significant resources for updates and typically remaining less dynamic post-deployment. In contrast, custom, domain-specific models can continuously adapt to their environment through tight feedback loops, with smaller models enabling cost-effective, frequent retraining. The result is a vertical-specific system that’s alive, evolving daily to tackle your customers’ exact challenges. It delivers a level of specialization and agility that bigger, broader models can’t keep up with.